Python API¶
This section includes information for using the pure Python API of
bob.learn.mlp.
-
class
bob.learn.mlp.BackProp(batch_size, cost[, machine[, train_biases]]) → new BackProp¶ Bases:
bob.learn.mlp.TrainerBackProp(other) -> new BackProp
Sets an MLP to perform discrimination based on vanilla error back-propagation as defined in “Pattern Recognition and Machine Learning” by C.M. Bishop, chapter 5 or else, “Pattern Classification” by Duda, Hart and Stork, chapter 6.
To create a new trainer, either pass the batch-size, cost functor, machine and a biases-training flag or another trainer you’d like the parameters copied from.
Keyword parameters:
- batch_size, int
The size of each batch used for the forward and backward steps. If you set this to
1, then you are implementing stochastic training.Note
This setting affects the convergence.
- cost,
bob.learn.mlp.Cost - An object that can calculate the cost at every iteration.
- machine,
bob.learn.mlp.Machine - This parameter that will be used as a basis for this trainer’s internal properties (cache sizes, for instance).
- train_biases, bool
- A boolean indicating if we should train the biases weights (set
it to
True) or not (set it toFalse). - other,
bob.learn.mlp.Trainer - Another trainer from which this new copy will get its properties from. If you use this constructor than a new (deep) copy of the trainer is created.
-
backward_step()¶ Backwards a batch of data through the MLP and updates the internal buffers (errors and derivatives).
-
batch_size¶ How many examples should be fed each time through the network for testing or training. This number reflects the internal sizes of structures setup to accomodate the input and the output of the network.
-
bias_derivatives¶ The calculated derivatives of the cost w.r.t. to the specific biases of the network, organized to match the organization of biases of the machine being trained.
-
cost(target) → float¶ o.cost(machine, input, target) -> float
Calculates the cost for a given target.
The cost for a given target is defined as the sum of individual costs for every output in the current network, averaged over all the examples.
You can use this function in two ways. Either by initially calling
forward_step()passingmachineandinputand then calling this method with just thetargetor passing all three objects in a single call. With the latter strategy, theforward_step()will be called internally.This function returns a single scalar, of
floattype, representing the average cost for all input given the expected target.
-
cost_object¶ An object, derived from
bob.learn.mlp.Cost(e.g.bob.learn.mlp.SquareErrororbob.learn.mlp.CrossEntropyLoss), that is used to evaluate the cost (a.k.a. loss) and the derivatives given the input, the target and the MLP structure.
-
derivatives¶ The calculated derivatives of the cost w.r.t. to the specific weights of the network, organized to match the organization of weights of the machine being trained.
-
error¶ The error (a.k.a.
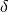 ‘s) back-propagated through the
network, given an input and a target.
‘s) back-propagated through the
network, given an input and a target.
-
forward_step()¶ Forwards a batch of data through the MLP and updates the internal buffers.
The number of hidden layers on the target machine.
-
initialize()¶ Initialize the trainer with the given machine
-
is_compatible()¶ Checks if a given machine is compatible with inner settings
-
learning_rate¶ The learning rate (
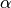 ) to be used for the
back-propagation (defaults to
) to be used for the
back-propagation (defaults to 0.1).
-
momentum¶ The momentum (
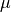 ) to be used for the back-propagation.
This value allows for some memory on previous weight updates to
be used for the next update (defaults to
) to be used for the back-propagation.
This value allows for some memory on previous weight updates to
be used for the next update (defaults to 0.0).
-
output¶ The outputs of each neuron in the network
-
previous_bias_derivatives¶ The derivatives of the cost w.r.t. to the specific biases of the network, from the previous training step. The derivatives are arranged to match the organization of weights of the machine being trained.
-
previous_derivatives¶ The derivatives of the cost w.r.t. to the specific weights of the network, from the previous training step. The derivatives are arranged to match the organization of weights of the machine being trained.
-
reset()¶ Re-initializes the whole training apparatus to start training a new machine. This will effectively reset previous derivatives to zero.
-
set_bias_derivative()¶ Sets the cost derivative w.r.t. the biases for a given layer.
-
set_derivative()¶ Sets the cost derivative w.r.t. the weights for a given layer.
-
set_error()¶ Sets the error for a given layer in the network.
-
set_output()¶ Sets the output for a given layer in the network.
-
set_previous_bias_derivative()¶ Sets the cost bias derivative for a given bias layer (index).
-
set_previous_derivative()¶ Sets the previous cost derivative for a given weight layer (index).
-
train(machine, input, target) → None¶ Trains the MLP to perform discrimination using error back-propagation
Call this method to train the MLP to perform discrimination using back-propagation with (optional) momentum. Concretely, this executes the following update rule for the weights (and biases, optionally):
![\begin{align}
\theta_j(t+1) & = & \theta_j - [ (1-\mu)\Delta\theta_j(t) + \mu\Delta\theta_j(t-1) ] \\
\Delta\theta_j(t) & = & \alpha\frac{1}{N}\sum_{i=1}^{N}\frac{\partial J(x_i; \theta)}{\partial \theta_j}
\end{align}](../../../_images/math/f5bea9085831e3135641d59f201bf47af907169a.png)
The training is executed outside the machine context, but uses all the current machine layout. The given machine is updated with new weights and biases at the end of the training that is performed a single time.
You must iterate (in Python) as much as you want to refine the training.
The machine given as input is checked for compatibility with the current initialized settings. If the two are not compatible, an exception is thrown.
Note
In BackProp, training is done in batches. You should set the batch size properly at class initialization or use setBatchSize().
Note
The machine is not initialized randomly at each call to this method. It is your task to call
bob.learn.mlp.Machine.randomize()once at the machine you want to train and then call this method as many times as you think is necessary. This design allows for a stopping criteria to be encoded outside the scope of this trainer and for this method to only focus on applying the training when requested to. Stochastic training can be executed by setting thebatch_sizeto 1.Keyword arguments:
- machine,
bob.learn.mlp.Machine - The machine that will be trained. You must have called
bob.learn.mlp.Trainer.initialize()which a similarly configured machine before being able to call this method, or an exception may be thrown. - input, array-like, 2D with
float64as data type - A 2D
numpy.ndarraywith 64-bit floats containing the input data for the MLP to which this training step will be based on. The matrix should be organized so each input (example) lies on a single row ofinput. - target, array-like, 2D with
float64as data type - A 2D
numpy.ndarraywith 64-bit floats containing the target data for the MLP to which this training step will be based on. The matrix should be organized so each target lies on a single row oftarget, matching each input example ininput.
- machine,
-
train_biases¶ A flag, indicating if this trainer will adjust the biases of the network
-
class
bob.learn.mlp.Cost¶ Bases:
objectA base class for evaluating the performance cost.
This is the base class for all concrete (C++ only) loss function implementations. You cannot instantiate objects of this type directly, use one of the derived classes.
-
error(output, target[, result]) → result¶ Computes the back-propagated error for a given MLP
outputlayer.Computes the back-propagated error for a given MLP
outputlayer, given its activation function and outputs - i.e., the error back-propagated through the last layer neuron up to the synapse connecting the last hidden layer to the output layer.This implementation allows for optimization in the calculation of the back-propagated errors in cases where there is a possibility of mathematical simplification when using a certain combination of cost-function and activation. For example, using a ML-cost and a logistic activation function.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type and
extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can pass
this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult. - Returns the cost as a scalar, if the input were scalars or as
- an array with matching size of
outputandtargetotherwise.
-
f(output, target[, result]) → result¶ Computes the cost, given the current and expected outputs.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
f_prime(output, target[, result]) → result¶ Computes the derivative of the cost w.r.t. output.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
-
class
bob.learn.mlp.CrossEntropyLoss(actfun) → new CrossEntropyLoss functor¶ Bases:
bob.learn.mlp.CostCalculates the Cross Entropy Loss between output and target.
The cross entropy loss is defined as follows:
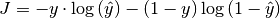
where
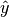 is the output estimated by your machine and
is the output estimated by your machine and
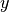 is the expected output.
is the expected output.Keyword arguments:
- actfun
The activation function object used at the last layer. If you set this to
bob.learn.activation.Logistic, a mathematical simplification is possible in whichbackprop_error()can benefit increasing the numerical stability of the training process. The simplification goes as follows: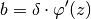
But, for the cross-entropy loss:
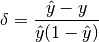
and
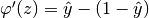 , so:
, so: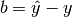
-
error(output, target[, result]) → result¶ Computes the back-propagated error for a given MLP
outputlayer.Computes the back-propagated error for a given MLP
outputlayer, given its activation function and outputs - i.e., the error back-propagated through the last layer neuron up to the synapse connecting the last hidden layer to the output layer.This implementation allows for optimization in the calculation of the back-propagated errors in cases where there is a possibility of mathematical simplification when using a certain combination of cost-function and activation. For example, using a ML-cost and a logistic activation function.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type and
extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can pass
this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult. - Returns the cost as a scalar, if the input were scalars or as
- an array with matching size of
outputandtargetotherwise.
-
f(output, target[, result]) → result¶ Computes the cost, given the current and expected outputs.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
f_prime(output, target[, result]) → result¶ Computes the derivative of the cost w.r.t. output.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
logistic_activation¶ Tells if this functor is set to operate together with a
bob.learn.activation.Logisticactivation function.
-
class
bob.learn.mlp.DataShuffler(data, target) → New DataShuffler¶ Bases:
objectServes data from a training set, in a random way.
Objects of this class are capable of being populated with data from one or multiple classes and matching target values. Once setup, the shuffer can randomly select a number of vectors and accompaning targets for the different classes, filling up user containers.
Data shufflers are particular useful for training neural networks.
Keyword arguments:
- data, sequence of array-like 2D float64
- The input data are divided into sets corresponding to the elements of each input class. Within the class array, each row is expected to correspond to one observation of that class.
- target, sequence of array-like 1D float64
- The target arrays correspond to the targets for each of the
input arrays. The number of targets must match the number of
2D array objects given in
data.
-
auto_stdnorm¶ Defines if we use or not automatic standard (Z) normalisation
-
data_width¶ The number of features (i.e. the width) of each data vector
-
draw([n, [data, [target, [rng]]]]) -> (data, target)¶ Draws a random number of data-target pairs from the input data.
This method will draw a given number
nof data-target pairs from the input data, randomly. You can specific the destination containersdataandtargetwhich, if provided, must be 2D arrays of type float64` with as many rows asnand as many columns as the data and target widths provided upon construction.If
nis not specified, than that value is taken from the number of rows in eitherdataortarget, whichever is provided. It is an error not to provide one ofdata,targetorn.If a random generator
rngis provided, it must of the typebob.core.random.mt19937. In this case, the shuffler is going to use this generator instead of its internal one. This mechanism is useful for repeating draws in case of tests.Independently if
dataand/ortargetis provided, this function will always return a tuple containing thedataandtargetarrays with the random data picked from the user input. If eitherdataortargetare not provided by the user, then they are created internally and returned.
-
stdnorm() -> (mean, stddev)¶ Returns the standard normalisation parameters (mean and std. deviation) for the input data. Returns a tuple
(mean, stddev), which are 1D float64 arrays with as many entries aso.data_width.
-
target_width¶ The number of components (i.e. the width) of target vectors
-
class
bob.learn.mlp.Machine(shape)¶ Bases:
objectMachine(config) Machine(other)
A Multi-layer Perceptron Machine.
An MLP Machine is a representation of a Multi-Layer Perceptron. This implementation is feed-forward and fully-connected. The implementation allows setting of input normalization values and a global activation function. References to fully-connected feed-forward networks:
Bishop’s Pattern Recognition and Machine Learning, Chapter 5. Figure 5.1 shows what is programmed.MLPs normally are multi-layered systems, with 1 or more hidden layers. As a special case, this implementation also supports connecting the input directly to the output by means of a single weight matrix. This is equivalent of a
bob.learn.linear.Machine, with the advantage it can be trained by trainers defined in this package.An MLP can be constructed in different ways. In the first form, the user specifies the machine shape as sequence (e.g. a tuple). The sequence should contain the number of inputs (first element), number of outputs (last element) and the number of neurons in each hidden layer (elements between the first and last element of given tuple). The activation function will be set to hyperbolic tangent. The machine is remains uninitialized. In the second form the user passes a pre-opened HDF5 file pointing to the machine information to be loaded in memory. Finally, in the last form (copy constructor), the user passes another
Machinethat will be fully copied.-
biases¶ Bias to the output units of this linear machine, to be added to the output before activation.
-
forward(input[, output]) → array¶ Projects
inputthrough its internal structure. Ifoutputis provided, place output there instead of allocating a new array.The
input(andoutput) arrays can be either 1D or 2D 64-bit float arrays. If one provides a 1D array, theoutputarray, if provided, should also be 1D, matching the output size of this machine. If one provides a 2D array, it is considered a set of vertically stacked 1D arrays (one input per row) and a 2D array is produced or expected inoutput. Theoutputarray in this case shall have the same number of rows as theinputarray and as many columns as the output size for this machine.Note
This method only accepts 64-bit float arrays as input or output.
The hidden neurons activation function - by default, the hyperbolic tangent function. The current implementation only allows setting one global value for all hidden layers.
-
input_divide¶ Input division factor, before feeding data through the weight matrix W. The division is applied just after subtraction - by default, it is set to 1.0.
-
input_subtract¶ Input subtraction factor, before feeding data through the weight matrix W. The subtraction is the first applied operation in the processing chain - by default, it is set to 0.0.
-
is_similar_to(other[, r_epsilon=1e-5[, a_epsilon=1e-8]]) → bool¶ Compares this MLP with the
otherone to be approximately the same.The optional values
r_epsilonanda_epsilonrefer to the relative and absolute precision for theweights,biasesand any other values internal to this machine.
-
load(f) → None¶ Loads itself from a
bob.io.base.HDF5File
-
output_activation¶ The output activation function - by default, the hyperbolic tangent function. The output provided by the output activation function is passed, unchanged, to the user.
-
randomize([lower_bound[, upper_bound[, rng]]]) → None¶ Resets parameters of this MLP using a random number generator.
Sets all weights and biases of this MLP, with random values between
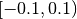 as advised in textbooks.
as advised in textbooks.Values are drawn using
boost::uniform_realclass. The seed is picked using a time-based algorithm. Different calls spaced of at least 10 microseconds (machine clock) will be seeded differently. If lower and upper bound values are given, then new parameters are taken from[lower_bound, upper_bound), according to theboost::randomdocumentation. The user may also pass the random number generator to be used. This allows you to set the seed to a specific value before randomizing the MLP parameters. If not set, this method will use an internal random number generator with a seed which is based on the current time.
-
save(f) → None¶ Saves itself at a
bob.io.base.HDF5File
-
shape¶ A tuple that represents the size of the input vector followed by the size of the output vector in the format
(input, output).
-
weights¶ Weight matrix to which the input is projected to. The output of the project is fed subject to bias and activation before being output.
-
-
class
bob.learn.mlp.RProp(batch_size, cost[, trainer[, train_biases]]) → new RProp¶ Bases:
bob.learn.mlp.TrainerRProp(other) -> new RProp
Sets an MLP to perform discrimination based on RProp: A Direct Adaptive Method for Faster Backpropagation Learning: The RPROP Algorithm, by Martin Riedmiller and Heinrich Braun on IEEE International Conference on Neural Networks, pp. 586–591, 1993.
To create a new trainer, either pass the batch-size, cost functor, machine and a biases-training flag or another trainer you’d like the parameters copied from.
Note
RProp is a “batch” training algorithm. Do not try to set batch_size to a value which is too low.
Keyword parameters:
- batch_size, int
The size of each batch used for the forward and backward steps. If you set this to
1, then you are implementing stochastic training.Note
This setting affects the convergence.
- cost,
bob.learn.mlp.Cost - An object that can calculate the cost at every iteration.
- machine,
bob.learn.mlp.Machine - This parameter that will be used as a basis for this trainer’s internal properties (cache sizes, for instance).
- train_biases, bool
- A boolean indicating if we should train the biases weights (set
it to
True) or not (set it toFalse). - other,
bob.learn.mlp.Trainer - Another trainer from which this new copy will get its properties from. If you use this constructor than a new (deep) copy of the trainer is created.
-
backward_step()¶ Backwards a batch of data through the MLP and updates the internal buffers (errors and derivatives).
-
batch_size¶ How many examples should be fed each time through the network for testing or training. This number reflects the internal sizes of structures setup to accomodate the input and the output of the network.
-
bias_deltas¶ Current settings for the bias update (
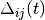 )
)
-
bias_derivatives¶ The calculated derivatives of the cost w.r.t. to the specific biases of the network, organized to match the organization of biases of the machine being trained.
-
cost(target) → float¶ o.cost(machine, input, target) -> float
Calculates the cost for a given target.
The cost for a given target is defined as the sum of individual costs for every output in the current network, averaged over all the examples.
You can use this function in two ways. Either by initially calling
forward_step()passingmachineandinputand then calling this method with just thetargetor passing all three objects in a single call. With the latter strategy, theforward_step()will be called internally.This function returns a single scalar, of
floattype, representing the average cost for all input given the expected target.
-
cost_object¶ An object, derived from
bob.learn.mlp.Cost(e.g.bob.learn.mlp.SquareErrororbob.learn.mlp.CrossEntropyLoss), that is used to evaluate the cost (a.k.a. loss) and the derivatives given the input, the target and the MLP structure.
-
delta_max¶ Maximal weight update (defaults to
50.0)
-
delta_min¶ Minimal weight update (defaults to
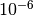 )
)
-
delta_zero¶ Initial weight update (defaults to
0.1)
-
deltas¶ Current settings for the weight update (
)
-
derivatives¶ The calculated derivatives of the cost w.r.t. to the specific weights of the network, organized to match the organization of weights of the machine being trained.
-
error¶ The error (a.k.a.
‘s) back-propagated through the
network, given an input and a target.
-
eta_minus¶ Learning de-enforcement parameter (defaults to
0.5)
-
eta_plus¶ Learning enforcement parameter (defaults to
1.2)
-
forward_step()¶ Forwards a batch of data through the MLP and updates the internal buffers.
The number of hidden layers on the target machine.
-
initialize()¶ Initialize the trainer with the given machine
-
is_compatible()¶ Checks if a given machine is compatible with inner settings
-
output¶ The outputs of each neuron in the network
-
previous_bias_derivatives¶ The derivatives of the cost w.r.t. to the specific biases of the network, from the previous training step. The derivatives are arranged to match the organization of weights of the machine being trained.
-
previous_derivatives¶ The derivatives of the cost w.r.t. to the specific weights of the network, from the previous training step. The derivatives are arranged to match the organization of weights of the machine being trained.
-
reset()¶ Re-initializes the whole training apparatus to start training a new machine. This will effectively reset previous derivatives to zero.
-
set_bias_delta()¶ Sets the bias delta for a given bias layer.
-
set_bias_derivative()¶ Sets the cost derivative w.r.t. the biases for a given layer.
-
set_delta()¶ Sets the delta for a given weight layer.
-
set_derivative()¶ Sets the cost derivative w.r.t. the weights for a given layer.
-
set_error()¶ Sets the error for a given layer in the network.
-
set_output()¶ Sets the output for a given layer in the network.
-
set_previous_bias_derivative()¶ Sets the cost bias derivative for a given bias layer (index).
-
set_previous_derivative()¶ Sets the previous cost derivative for a given weight layer (index).
-
train(machine, input, target) → None¶ Trains the MLP to perform discrimination using RProp
Resilient Back-propagation (R-Prop) is an efficient algorithm for gradient descent with local adpatation of the weight updates, which adapts to the behaviour of the chosen error function.
Concretely, this executes the following update rule for the weights (and biases, optionally) and respective
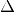 ‘s (the
current weight updates):
‘s (the
current weight updates):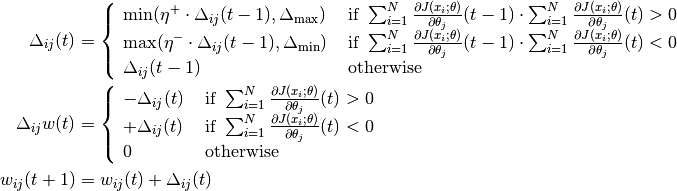
The following parameters are set by default and suggested by the article:
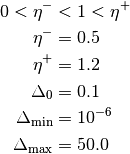
The training is executed outside the machine context, but uses all the current machine layout. The given machine is updated with new weights and biases at the end of the training that is performed a single time. Iterate as much as you want to refine the training.
The machine given as input is checked for compatibility with the current initialized settings. If the two are not compatible, an exception is thrown.
Note
In RProp, training is done in batches. You should set the batch size adequately at class initialization or use setBatchSize().
Note
The machine is not initialized randomly at each call to this method. It is your task to call
bob.learn.mlp.Machine.randomize()once at the machine you want to train and then call this method as many times as you think are necessary. This design allows for a training criteria to be encoded outside the scope of this trainer and to this type to focus only on applying the training when requested to.Keyword arguments:
- machine,
bob.learn.mlp.Machine - The machine that will be trained. You must have called
bob.learn.mlp.Trainer.initialize()which a similarly configured machine before being able to call this method, or an exception may be thrown. - input, array-like, 2D with
float64as data type - A 2D
numpy.ndarraywith 64-bit floats containing the input data for the MLP to which this training step will be based on. The matrix should be organized so each input (example) lies on a single row ofinput. - target, array-like, 2D with
float64as data type - A 2D
numpy.ndarraywith 64-bit floats containing the target data for the MLP to which this training step will be based on. The matrix should be organized so each target lies on a single row oftarget, matching each input example ininput.
- machine,
-
train_biases¶ A flag, indicating if this trainer will adjust the biases of the network
-
class
bob.learn.mlp.SquareError(actfun) → new SquareError functor¶ Bases:
bob.learn.mlp.CostCalculates the Square-Error between output and target.
The square error is defined as follows:
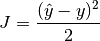
where
is the output estimated by your machine and
is the expected output.Keyword arguments:
- actfun
- The activation function object used at the last layer
-
error(output, target[, result]) → result¶ Computes the back-propagated error for a given MLP
outputlayer.Computes the back-propagated error for a given MLP
outputlayer, given its activation function and outputs - i.e., the error back-propagated through the last layer neuron up to the synapse connecting the last hidden layer to the output layer.This implementation allows for optimization in the calculation of the back-propagated errors in cases where there is a possibility of mathematical simplification when using a certain combination of cost-function and activation. For example, using a ML-cost and a logistic activation function.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type and
extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can pass
this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult. - Returns the cost as a scalar, if the input were scalars or as
- an array with matching size of
outputandtargetotherwise.
-
f(output, target[, result]) → result¶ Computes the cost, given the current and expected outputs.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
f_prime(output, target[, result]) → result¶ Computes the derivative of the cost w.r.t. output.
Keyword arguments:
- output, ND array, float64 | scalar
- Real output from the machine. May be a N-dimensional array or a plain scalar.
- target, ND array, float64 | scalar
- Target output you are training to achieve. The data type
and extents for this object must match that of
target. - result (optional), ND array, float64
- Where to place the result from the calculation. You can
pass this argument if the input are N-dimensional arrays.
Otherwise, it is an error to pass such a container. If the
inputs are arrays and an object for
resultis passed, then its dimensions and data-type must match that of bothoutputandresult.
Returns the cost as a scalar, if the input were scalars or as an array with matching size of
outputandtargetotherwise.
-
class
bob.learn.mlp.Trainer(batch_size, cost[, trainer[, train_biases]]) → new Trainer¶ Bases:
objectTrainer(other) -> new Trainer
The base python class for MLP trainers based on cost derivatives.
You should use this class when you want to create your own MLP trainers and re-use the base infrastructured provided by this module, such as the computation of partial derivatives (using the
backward_step()method).To create a new trainer, either pass the batch-size, cost functor, machine and a biases-training flag or another trainer you’d like the parameters copied from.
Keyword parameters:
- batch_size, int
The size of each batch used for the forward and backward steps. If you set this to
1, then you are implementing stochastic training.Note
This setting affects the convergence.
- cost,
bob.learn.mlp.Cost - An object that can calculate the cost at every iteration.
- machine,
bob.learn.mlp.Machine - This parameter that will be used as a basis for this trainer’s internal properties (cache sizes, for instance).
- train_biases, bool
- A boolean indicating if we should train the biases weights (set
it to
True) or not (set it toFalse). - other,
bob.learn.mlp.Trainer - Another trainer from which this new copy will get its properties from. If you use this constructor than a new (deep) copy of the trainer is created.
-
backward_step()¶ Backwards a batch of data through the MLP and updates the internal buffers (errors and derivatives).
-
batch_size¶ How many examples should be fed each time through the network for testing or training. This number reflects the internal sizes of structures setup to accomodate the input and the output of the network.
-
bias_derivatives¶ The calculated derivatives of the cost w.r.t. to the specific biases of the network, organized to match the organization of biases of the machine being trained.
-
cost(target) → float¶ o.cost(machine, input, target) -> float
Calculates the cost for a given target.
The cost for a given target is defined as the sum of individual costs for every output in the current network, averaged over all the examples.
You can use this function in two ways. Either by initially calling
forward_step()passingmachineandinputand then calling this method with just thetargetor passing all three objects in a single call. With the latter strategy, theforward_step()will be called internally.This function returns a single scalar, of
floattype, representing the average cost for all input given the expected target.
-
cost_object¶ An object, derived from
bob.learn.mlp.Cost(e.g.bob.learn.mlp.SquareErrororbob.learn.mlp.CrossEntropyLoss), that is used to evaluate the cost (a.k.a. loss) and the derivatives given the input, the target and the MLP structure.
-
derivatives¶ The calculated derivatives of the cost w.r.t. to the specific weights of the network, organized to match the organization of weights of the machine being trained.
-
error¶ The error (a.k.a.
‘s) back-propagated through the
network, given an input and a target.
-
forward_step()¶ Forwards a batch of data through the MLP and updates the internal buffers.
The number of hidden layers on the target machine.
-
initialize()¶ Initialize the trainer with the given machine
-
is_compatible()¶ Checks if a given machine is compatible with inner settings
-
output¶ The outputs of each neuron in the network
-
set_bias_derivative()¶ Sets the cost derivative w.r.t. the biases for a given layer.
-
set_derivative()¶ Sets the cost derivative w.r.t. the weights for a given layer.
-
set_error()¶ Sets the error for a given layer in the network.
-
set_output()¶ Sets the output for a given layer in the network.
-
train_biases¶ A flag, indicating if this trainer will adjust the biases of the network
-
bob.learn.mlp.number_of_parameters(machine) → scalar¶ number_of_parameters(weights, biases) -> scalar
Returns the total number of parameters in an MLP.
Keyword parameters:
- machine,
bob.learn.mlp.Machine - Using the first call API, counts the total number of parameters in an MLP.
- weights, sequence of 2D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 2D arrays of 64-bit floats representing the weights for the MLP you wish to count the parameters from.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.Other checks are disabled as this is considered an expert API. If you plan to unroll the weights and biases on a
bob.learn.mlp.Machine, notice that in a givenweightssequence the number of outputs in layerkmust match the number of inputs on layerk+1and the number of bias on layerk. In practice, you must assert thatweights[k].shape[1] == weights[k+1].shape[0]and. thatweights[k].shape[1] == bias[k].shape[0].- biases, sequence of 1D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 1D arrays of 64-bit floats representing the biases for the MLP you wish to number_of_parameters the parameters into.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.
- machine,
-
bob.learn.mlp.roll(machine, parameters) → parameters¶ roll(weights, biases, parameters) -> parameters
Roll the parameters (weights and biases) from a 64-bit float 1D array.
This function will roll the MLP machine weights and biases from a single 1D array of 64-bit floats. This procedure is useful for adapting generic optimization procedures for the task of training MLPs.
Keyword parameters:
- machine,
bob.learn.mlp.Machine - An MLP that will have its weights and biases rolled from a 1D array
- weights, sequence of 2D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 2D arrays of 64-bit floats representing the weights for the MLP you wish to roll the parameters into using this argument.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.Other checks are disabled as this is considered an expert API. If you plan to roll the weights and biases on a
bob.learn.mlp.Machine, notice that in a givenweightssequence, the number of outputs in layerkmust match the number of inputs on layerk+1and the number of biases on layerk. In practice, you must assert thatweights[k].shape[1] == weights[k+1].shape[0]and. thatweights[k].shape[1] == bias[k].shape[0].- biases, sequence of 1D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 1D arrays of 64-bit floats representing the biases for the MLP you wish to roll the parameters into.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.- parameters, 1D 64-bit float array
You may decide to pass the array in which the parameters will be placed using this variable. In this case, the size of the vector must match the total number of parameters available on the input machine or discrete weights and biases. If you decided to omit this parameter, then a vector with the appropriate size will be allocated internally and returned.
You can use py:func:number_of_parameters to calculate the total length of the required
parametersvector, in case you wish to supply it.
- machine,
-
bob.learn.mlp.unroll(machine[, parameters]) → parameters¶ unroll(weights, biases, [parameters]) -> parameters
Unroll the parameters (weights and biases) into a 64-bit float 1D array.
This function will unroll the MLP machine weights and biases into a single 1D array of 64-bit floats. This procedure is useful for adapting generic optimization procedures for the task of training MLPs.
Keyword parameters:
- machine,
bob.learn.mlp.Machine - An MLP that will have its weights and biases unrolled into a 1D array
- weights, sequence of 2D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 2D arrays of 64-bit floats representing the weights for the MLP you wish to unroll.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.Other checks are disabled as this is considered an expert API. If you plan to unroll the weights and biases on a
bob.learn.mlp.Machine, notice that in a givenweightssequence, the number of outputs in layerkmust match the number of inputs on layerk+1and the number of biases on layerk. In practice, you must assert thatweights[k].shape[1] == weights[k+1].shape[0]and. thatweights[k].shape[1] == bias[k].shape[0].- biases, sequence of 1D 64-bit float arrays
If you choose the second calling strategy, then pass a sequence of 1D arrays of 64-bit floats representing the biases for the MLP you wish to unroll.
Note
In this case, both this sequence and
biasesmust have the same length. This is the sole requirement.- parameters, 1D 64-bit float array
You may decide to pass the array in which the parameters will be placed using this variable. In this case, the size of the vector must match the total number of parameters available on the input machine or discrete weights and biases. If you decided to omit this parameter, then a vector with the appropriate size will be allocated internally and returned.
You can use py:func:number_of_parameters to calculate the total length of the required
parametersvector, in case you wish to supply it.
- machine,